LevelDB 架构简介
LevelDB 是 Google 开源的一个用 C++ 语言开发的键值存储库,它提供了简单的 KV 的接口,通过这些接口能够实现高效的数据的存取。RocksDB 就是基于 LevelDB 开发的键值数据库,目前已经被广泛应用于各种新一代的分布式数据库中。
LevelDB 的原理
LevelDB 基于 LSM-Tree 数据结构,对于数据查询提供了Get接口,通过一个 key 值对数据进行查询。对于数据操作,提供了Put,Delete这两种接口,用于数据的写入和删除。在 LevelDB 的内部实现中,Put操作就向数据库中写入一条记录,而不关心这条记录是插入一条新记录还是更新一条记录,Delete操作也是向数据库中写入一条标记为删除的记录。
LevelDB 的架构
LevelDB 架构如下图所示,分为内存部分和外存部分(hard driver)。内存中维护这两个 Memtable 对象 mem 和 imm,其中 mem 用于数据的写入,imm 是在 mem 的大小达到一定阈值时,由 mem 切换而来,也就是说 imm 其实就是上一个用于写入(或者查询)数据的 mem。Memtable 主要的数据结构是跳表(skiplist)。 外存部分由多个文件组成。首先就是 WAL 文件,这个文件的内容与 Memtable 文件一致,每次写入数据时,除了会向 Memtable 写入数据,还会将数据写入到 WAL 文件中。WAL 文件也会随着 Memtable 文件切换到 imm 时,重新创建一个新的文件。
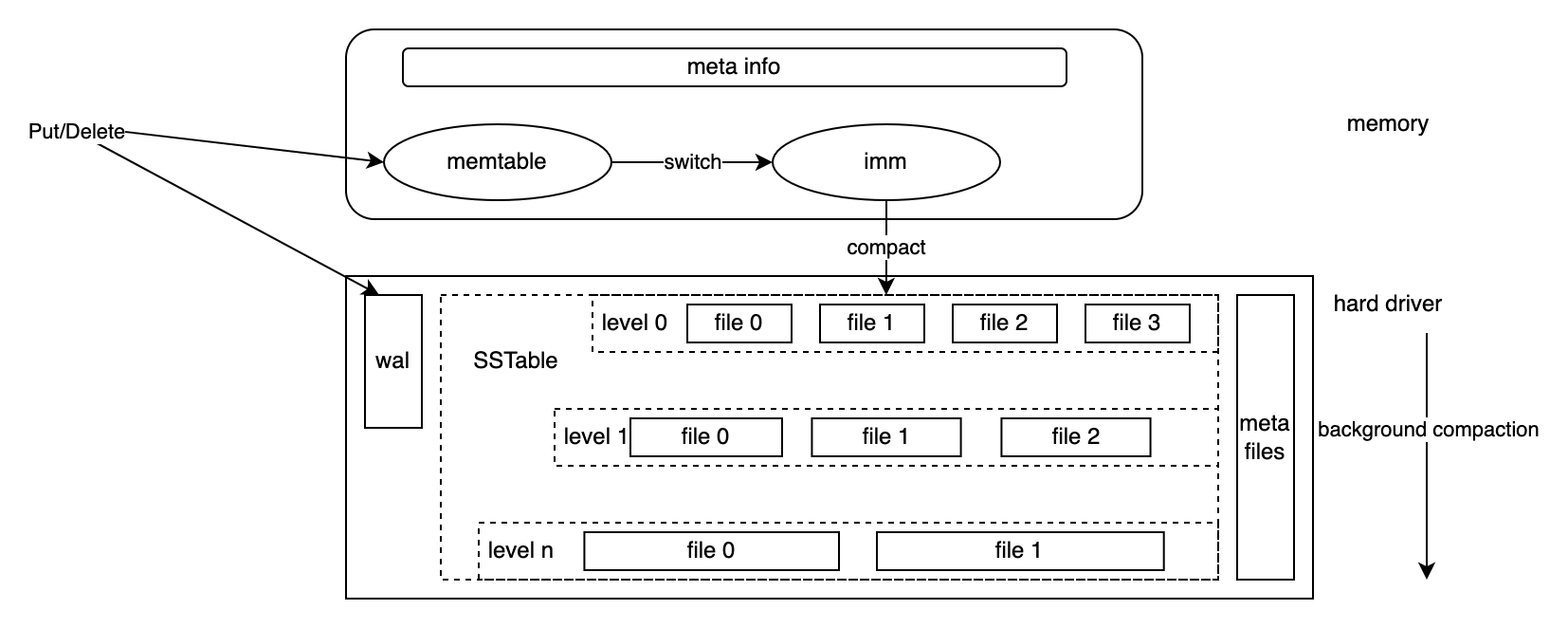
另外一种文件就是 SSTable(Sorted String Table)。从架构图可以看到,SSTable 由非常多的文件组成,而且这些文件是分级(Level)存储的。其中,Level 0 的文件由内存中的 imm 的数据 Compaction 而成,Level 1 的文件又是由 Level 0 的文件 Compaction 而成,除了 level 0 外,每一层都是由上一层的文件 Compaction 而成。SSTable 的一个主要的特点是它是有序的,每个文件中数据的最小值和最大值则存储在元数据文件中,也就是图中的 meta files。 元数据文件(meta files)主要存储了 LevelDB 运行过程中的元数据,比如每个 SSTable 文件的最小值,最大值,当前正在承载写入的 WAL 文件等等。
LevelDB 的 Compaction
在 LevelDB 中,Compaction 是一个非常重要的操作,这个操作会将 LevelDB 中各个 Level 的数据进行合并,生成新的 Level 的数据,在 LevelDB 运行过程中,会通过后台线程来执行 Compaction。比如对于内存中 Memtable 里的数据,当其数据量达到一定阈值时,LevelDB 会生成一个新的 Memtable 对象,旧的 Memtable 会成为不可变的对象,然后会由后台线程将数据写入到 level 0 的文件中。而后台线程也会检查每个 level 的文件数量,如果达到一定的阈值,则会启动一个线程来合并(Compaction)这些文件。 为什么要合并文件呢?因为 LevelDB 对数据的更新和删除都会写入一条新的记录,而不是对数据进行删除和更新,这样其实最新一条记录就代表了这条数据最新的状态,而旧版本的数据则是无效的,通过 Compaction 操作,LevelDB 只保留最新版本的数据,这样就不至于存放过多的无效数据。其实 Compaction 就是 LevelDB 中的一种垃圾回收(GC)。
总结
本文从 LevelDB 原理和架构的角度,对 LevelDB 进行了简单的介绍。其中 Memtable,SSTable 是 LevelDB 中最为核心的概念,Compaction 是 LevelDB 中最为核心的后台操作。