Apache Calcite 核心概念梳理
什么是 Apache Calcite
Calcite 的官方文档的一句话定义是:一个动态数据管理框架(a dynamic data management framework)。这个概念比较抽象,很难理解,那先来看看它提供了哪些功能点:
- 标准的 SQL 解析器,Calcite 定义了一套 SQL 语言的 AST(Abstract Syntax Tree),并且基于 javacc 实现了一个标准的 SQL 解析器。
- 基于关系代数的查询优化框架,Calcite 实现了 Volcano/Cascades 优化器模型,提供了基于规则(RBO)和基于代价(CBO)的优化器框架,并且提供了一些常见的优化规则。
- 数据(存储)适配器,Calcite 定义了一套数据访问接口,用于实现对存储层数据的访问,比如 Calcite 提供了 Cassandra, Druid,Redis 等数据库的适配器(Adpator)。Calcite 提供的适配器可以参考其 Adaptor 文档:
除了以上三大功能点外,Calcite 还提供了 JDBC 接口和数据库执行计划的执行器,支持解释执行器和代码生成执行。如果需要使用 Calcite 内置的执行器,需要生成 Calcite 执行器所需要的物理执行计划。从 Calcite 提供的功能,可以看到,它其实提供了实现数据库的查询优化功能的代码框架,基于它,再结合具体的数据存储引擎,就可以实现数据库的查询优化器和执行器了。Calcite 官方的 CSV 文件的例子就是实现了在 CSV 文件之上的 SQL 查询功能,具体的实现步骤见:https://calcite.apache.org/docs/tutorial.html。
在使用 Calcite 时,Calcite 并不要求将这三大功能点都使用上,而是可以按照自己的需求使用,每个功能点都定义了完整的接口,所以可以基于这些接口来扩展。比如已经有了 SQL 解析器了,但是想使用到 Calcite 的查询优化框架,那么可以利用 Calcite 的 Algebra builder 关系代数接口,将自有的 SQL 解析器的 AST 转换为 Calcite 定义的关系代数对象,然后再交给优化器框(Planner)来优化。
在 Calcite 的这些功能点中,SQL 解析和适配器(Adaptor)的概念比较简单,而查询优化器框架的概念最为复杂,所以本文重点介绍的是 Calcite 的查询优化器框架。
基本概念
初次接触 Calcite 时,会发现 Calcite 定义的概念过多,可能会有不知从何下手的感觉,下面会梳理一些 Calcite 的核心的概念。
SQL 解析中的基本概念
SqlNode
SqlNode 是对 Calcite 解析器的结果的 AST 的抽象,它的子类有 SqlIdentifier,SqlSelect,SqlOrderBy 等等,通过 org.apache.calcite.sql.parser.SqlParser#parseQuery() 接口就能解析一条 SQL 语句,并得到该 SQL 语句的 AST 的 SqlNode 对象。图 1 所示是一条 SQL 语句的 AST 的各个组成部分。
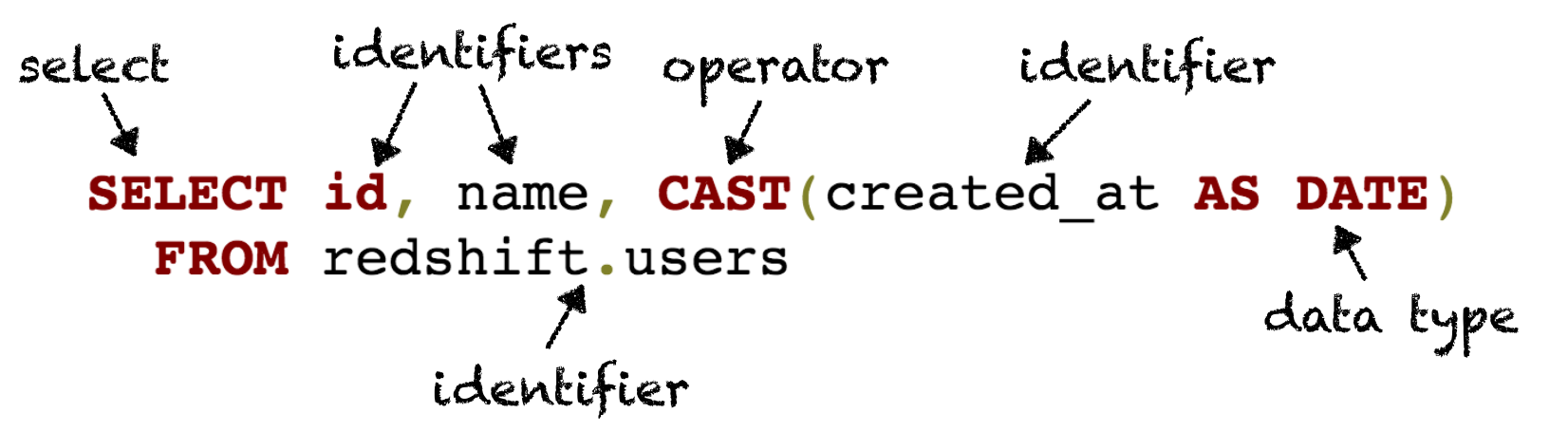 图1 SqlNode
图1 SqlNode
通过 parseQuery 方法解析出来的 SqlNode 对象,如图 2 所示
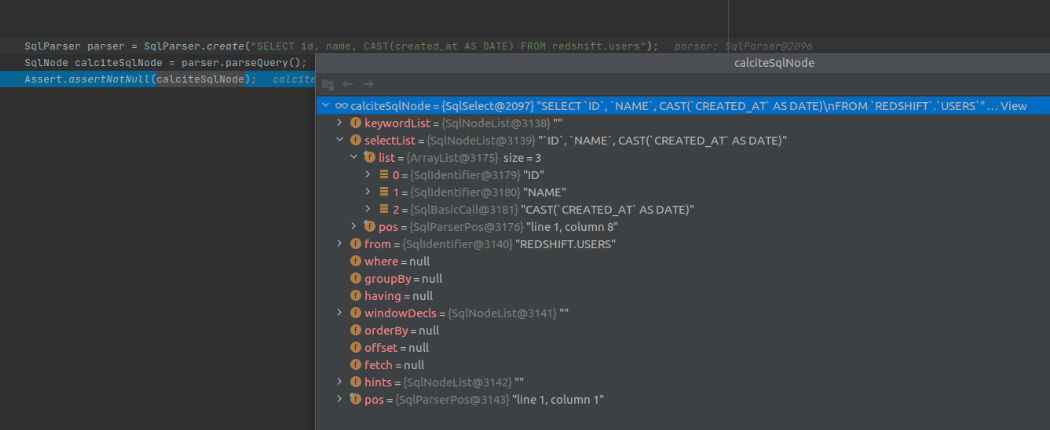 图2 SqlNode Object
图2 SqlNode Object
查询优化器中的基本概念
查询优化器是以关系代数为基础的,一般查询优化器的输入是逻辑关系代数表达式,输出是物理执行计划。在 Calcite 中,当一个 SQL 语句被解析为 SqlNode 对象之后,还需要对 SqlNode 做校验,然后将其转换为关系代数的表示,即 RelNode 所表示的关系代数对象,也称为逻辑查询计划。
RelNode
RelNode 表示一个关系表达式, 在 Calcite 中是用于表示关系代数的接口,比如 TableScan,Join,Union,Project,Filter 等都继承自 RelNode 接口。而每一个查询语句,在优化前都需要转换成关系代数表达式。比如下面这条 SELECT 语句和其逻辑执行计划分别如下所示。
- SQL 语句
select o1.order_id, o1.order_id, o1.user_id, o2.status
from t_order o1 join t_order_item o2 on o1.order_id = o2.order_id
where o1.status='FINISHED' and o2.order_item_id > 1024 and 1=1
order by o1.order_id desc
- 逻辑执行计划(关系代数表达式)
LogicalSort(sort0=[$0], dir0=[DESC])
LogicalProject(order_id=[$0], order_id0=[$0], user_id=[$1], status=[$6])
LogicalFilter(condition=[AND(=($2, CAST('FINISHED'):INTEGER NOT NULL), >($3, 1024), =(1, 1))])
LogicalJoin(condition=[=($0, $4)], joinType=[inner])
LogicalTableScan(table=[[logical_db, t_order]])
LogicalTableScan(table=[[logical_db, t_order_item]])
由于给出的 SQL 语句就是两个表的 join,然后再对 join 后的数据进行过滤,排序,最后选择出所需要的列,所以逻辑执行计划最底层是表扫描,表扫描的上层是 join,然后是数据过滤,过滤完的数据再做列投影,最后对结果进行排序。在逻辑执行计划中,Logical 前缀的表示为逻辑上的操作,它们并不与具体的执行绑定,查询优化器的作用就是对其进行优化,然后给出一个可以在某个执行器上执行的的物理执行计划,最后由执行器来执行。
不管是逻辑执行计划还是物理执行计划,它们都集成自 RelNode,因为物理执行计划本质上是对逻辑执行计划优化的结果,其实如果只给每种逻辑关系代数表达式实现一种物理执行方式,那么就不需要有优化成物理执行计划的 CBO 优化器了,这种情况下就只需要对逻辑执行计划做一些常见的有明确优化结果的优化了,也就是 RBO 优化器。
常见的关系代数表达式如图 3 所示。
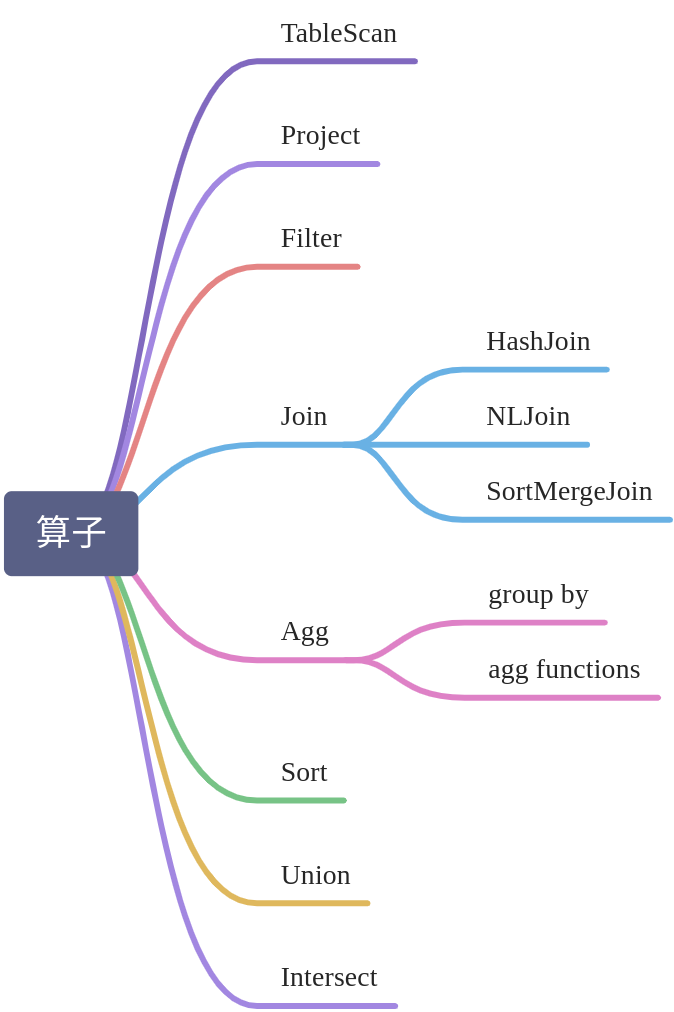
图3 SqlNode Object
RelTrait 与 RelTraitDef
RelTrait 表示 RelNode 的一种性质,用于指定物理执行属性,比如是否需要排序,数据的分布(distribution),它使用时由 RelTraitDef 来定义,目前分为三类:
- ConventionTraitDef,表示由何种数据处理引擎处理,对应的
RelTrait类型为Convention,逻辑执行计划中,其值默认为org.apache.calcite.plan.Convention#NONE,物理执行计划的对应的值在优化前,通过方法org.apache.calcite.plan.RelOptPlanner#changeTraits指定,Calcite 已经定义的有EnumerableConvention,BindableConvention,JdbcConvention等。如果为EnumerableConvention,那么生成的物理执行计划将由 Calcite 的 linq4j 引擎执行,此外每种Convention都对应具体的关系表达式的转换规则。 - RelCollationTraitDef,表示排序规则的定义,对应的
RelTrait为RelCollation。比如对于排序表达式(也称算子)org.apache.calcite.rel.core.Sort,就存在一个RelCollation类型的属性 collation。 - RelDistributionTraitDef,表示数据在物理存储上的分布方式,对应的
RelTrait为RelDistribution。
另外,对于每个 RelNode 对象,都会有 RelTraitSet,这是 RelTrait 的一个有序集合,RelNode 的 RelTrait 都是保存在该集合中的。
RelOptRule 和 RelOptPlanner
RelOptRule 和 RelOptPlanner 就是 Calcite 定义的优化框架的两个核心概念,简单的理解就是优化器框架(RelOptPlanner)通过执行优化规则(RelOptRule)来优化关系代数表达式。比如对于上面列出的 SQL 逻辑执行计划,如果直接执行这个逻辑执行计划,那么它表示先扫描两个表,在对两个表做 join,对 join 完成的结果,再做数据过滤,最后做投影和排序。有没有更有效的执行方式呢?当然有,因为 join 的执行方式通常是对两个表的数据按照 join 条件做连接,如果可以减少 join 的两个表的数据量,那 join 操作的效率就会提高。可以看到 LogicalFilter 中的条件其实可以直接放在 join 之前做掉,这样 Join 的数据就是执行了过滤条件后的目标数据,所以可以将逻辑执行计划变成如下逻辑执行计划。
LogicalSort(sort0=[$0], dir0=[DESC])
LogicalProject(order_id=[$0], order_id0=[$0], user_id=[$1], status=[$6])
LogicalJoin(condition=[=($0, $4)], joinType=[inner])
LogicalFilter(condition=[=($2, CAST('FINISHED'):INTEGER NOT NULL)])
LogicalTableScan(table=[[logical_db, t_order]])
LogicalFilter(condition=[>($0, 1024)])
LogicalTableScan(table=[[logical_db, t_order_item]])
这种优化方式称为条件下推(Push Down),也就是将 join 上层过滤条件下推到 join 的下层,以减小 join 操作的数据量。如果 join 操作所在的机器与数据不在同一台机器上,那么这种下推优化还可以减少网络传输的数据量,这也是分布式场景下常见的一种优化手段。
上述的优化由 Calcite 的 HepPlanner 执行 FilterIntoJoinRule 完成。FilterIntoJoinRule 就是 RelOptRule 的一个实现类,它的作用就是将 join 上的 Filter 条件下推到 join 之下,Calcite 内置了非常多的优化规则,具体见包 org.apache.calcite.rel.rules。HepPlanner 是 RelOptPlanner 的一种实现,它是一种启发式(Heuristic)的优化方式,所谓的启发式简单来说就是告诉优化器,存在这些优化手段,遇到了匹配的关系代数表达式,就可以执行对应的规则了。
Calcite 还实现了另一个 CBO 的优化框架 VolcanoPlanner,该优化器框架是 Volcano/Cascades 优化器模型的实现,通过 VolcanoPlanner 这个优化器框架以及优化规则,可以实现,将逻辑执行计划转换为物理执行计划。比如对以上优化过后的逻辑执行计划,使用 VolcanoPlanner 优化后的物理执行计划如下所示。与逻辑执行计划不一样的是,物理执行计划,确定了执行方式,比如逻辑执行计划中的 LogicalJoin,在物理执行计划中就对应 EnumerableHashJoin,它是 hash join 的一种实现。
EnumerableSort(sort0=[$0], dir0=[DESC])
EnumerableCalc(expr#0..7=[{inputs}], order_id=[$t0], order_id0=[$t0], user_id=[$t1], status=[$t6])
EnumerableHashJoin(condition=[=($0, $4)], joinType=[inner])
EnumerableCalc(expr#0..2=[{inputs}], expr#3=['FINISHED'], expr#4=[CAST($t3):INTEGER NOT NULL], expr#5=[=($t2, $t4)], proj#0..2=[{exprs}], $condition=[$t5])
EnumerableTableScan(table=[[logical_db, t_order]])
EnumerableCalc(expr#0..4=[{inputs}], expr#5=[1024], expr#6=[>($t0, $t5)], proj#0..4=[{exprs}], $condition=[$t6])
EnumerableTableScan(table=[[logical_db, t_order_item]])
总结
本文从 Calcite 的 SQL 解析器和查询优化框架的角度分析介绍了 Calcite 中的一些核心概念,这些概念对理解 Calcite 非常重要。文中未涉及 Adaptor 部分的概念介绍,因为 Adaptor 比较简单,动手跑一边 Calcite 的 CSV 的例子,基本就能理解了。