Apache Calcite HepPlanner 原理
什么是启发式优化
启发式优化(heuristic)是数据库查询优化中常用的而一种技术手段,也称为基于规则的优化(RBO)。其使用场景常常是作为基于代价的优化(CBO)的一种补充,因为基于代价的优化的一个缺点是优化本身是有代价的,在等价集合中找到最优的计划是仍然需要很多计算代价,所以基于代价的优化器可以使用启发式的方法来减少优化代价。比如 CBO 优化器在执行代价优化之前,会有一个查询改写(rewrite)的阶段,这个阶段就应用了启发式的优化手段。 启发式优化本质上是给定一组优化规则,通过将这组规则运用到关系代数表达式的每个节点上,从而优化关系代数表达式。而运用规则时,则会先判断规则是否适用于当前的关系代数表达式的节点,如果适用,则运用规则(执行转换),否则就继续试探下一个节点。这些规则是前人总结出来的宝贵经验,运用该规则优化通会带来优化的收益,但也不总是会带来优化收益。
Calcite 的启发式优化实现
在 Calcite 中,HepPlanner 是查询优化器(RelOptPlanner)的一个启发式优化实现。
使用 HepPlanner
如下代码片段是 HepPlanner 的使用方式,详细代码请参考 HepPlannerTest。
HepProgramBuilder hepProgramBuilder = HepProgram.builder();
hepProgramBuilder.addGroupBegin();
hepProgramBuilder.addRuleCollection(ImmutableList.of(CoreRules.FILTER_INTO_JOIN));
hepProgramBuilder.addGroupEnd();
HepPlanner hepPlanner = new HepPlanner(hepProgramBuilder.build(), null, true, null, RelOptCostImpl.FACTORY);
hepPlanner.setRoot(logicalRelNode);
RelNode best = hepPlanner.findBestExp();
使用 HepPlanner 分四步:
- 通过
HepProgramBuilder构建一个HepProgram,它制定了在优化过程中,使用规则的顺序。 - 创建
HepPlanner对象。 - 设置待优化的关系代数表达式(
setRoot)。 - 执行优化(
findBestExp),该方法计算得到的就是优化完的执行计划。
整个优化流程就是应用规则的过程,在上面的代码片段中仅仅使用了一个优化规则 CoreRules.FILTER_INTO_JOIN,该优化规则的作用是将 Join 上面的 Filter 中可以下推到 Join 下面的条件,下推下去。关于规则,可以参考文章 Apache Calcite 核心概念梳理。
比如,对于如下 SQL 语句,
select o1.order_id, o1.order_id, o1.user_id, o2.status from t_order o1 join t_order_item o2
on o1.order_id = o2.order_id where o1.status='FINISHED' and o2.order_item_id > 1024 and 1=1
由 AST 转换而成的关系代数表达式为。
LogicalProject(order_id=[$0], order_id0=[$0], user_id=[$1], status=[$6])
LogicalFilter(condition=[AND(=($2, 'FINISHED'), >($3, 1024), =(1, 1))])
LogicalJoin(condition=[=($0, $4)], joinType=[inner])
LogicalTableScan(table=[[logical_db, t_order]])
LogicalTableScan(table=[[logical_db, t_order_item]])
经过以上测试代码优化后的关系代数表达式为。
LogicalProject(order_id=[$0], order_id0=[$0], user_id=[$1], status=[$6])
LogicalJoin(condition=[=($0, $4)], joinType=[inner])
LogicalFilter(condition=[=($2, 'FINISHED')])
LogicalTableScan(table=[[logical_db, t_order]])
LogicalFilter(condition=[>($0, 1024)])
LogicalTableScan(table=[[logical_db, t_order_item]])
可以看到,Filter 条件已经被下推到 Join 下面了,下面的算子执行时会提前将不符合条件的数据给过滤掉,经过这样的下推优化,对于 Join 的执行,就能减少 Join 处理的数据量。
HepPlanner 核心概念
HepPlanner 优化流程是对一个有向图应用规则的过程,而这个有向图则是在设置关系代数表达式的过程中生成的(setRoot)。在优化过程中,首先是将关系代数表达式的树形结构转换成一个图形结构,再通过遍历加入到 HepPlanner 中的规则集合,对于每个规则集合应用到上述生成的图形结构中。
DirectedGraph
HepPlanner 在初始化关系代数表达式时(org.apache.calcite.plan.hep.HepPlanner#setRoot),会将逻辑关系代数表达式(RelNode)转换成一个图形结构(DirectedGraph的对象)。为什么需要将RelNode转换成图呢?因为 HepPlanner 在应用规则优化的过程中会使用新创建的关系代数表达式(RelNode)替换掉旧的,而 Calcite 定义的关系代数表达式本质上是一颗从上到下的树形结构,在 RelNode 中无法知道父节点是什么,所以通过将 RelNode 转换成图节点,可以有效的解决这种问题。查找父节点的代码可以参考 org.apache.calcite.plan.hep.HepPlanner#applyTransformationResults 该方法是在应用完规则以后,使用转换得到的新的节点,替换旧的关系代数表达式中节点的方法。
DirectedGraph的默认实现是DefaultDirectedGraph,在DefaultDirectedGraph中有代表所有节点的属性vertexMap和代表所有边的属性edges,它们的元素分别为HepRelVertex 和 DefaultEdge。其中vertexMap属性是 Map 结构,其键类型是HepRelVertex,值的类型是VertexInfo,它表示每个节点的出线和入线。
比如,对于上述的 SQL 生成的关系代数表达式,其树形结构,如下图所示。
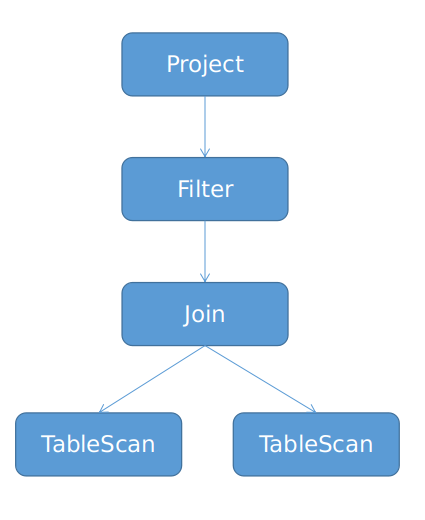
各个节点与上述优化前的关系代数表达式对应(算子名称去掉了 Logical 前缀)。而转换成图形结构后,如下图所示。
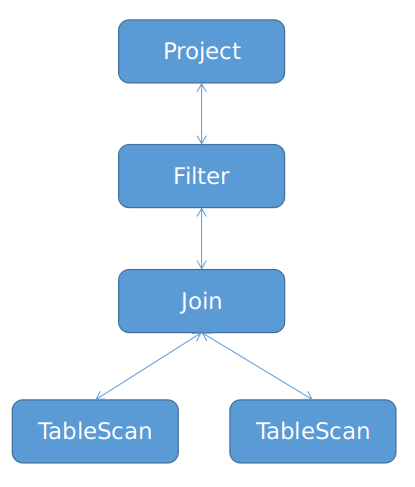
每个节点都有出线和入线(图中表示为双箭头)。
HepPlanner 优化流程
HepPlanner 分为初始化和优化两个流程,初始化会将关系代数表达式(RelNode)转换为图(DirectedGraph),优化流程才是真正的遍历和运用规则来优化关系代数表达式。
初始化setRoot
setRoot核心逻辑是调用方法org.apache.calcite.plan.hep.HepPlanner#addRelToGraph将当前的 RelNode添加到图(graph)中,对于每个RelNode都会先将其子节点加入到图中,再将当前节点生成节点(HepRelVertex)和边(DefaultEdge)加入到图中。从HepRelVertex定义的代码可以看到,其属性currentRel就是当前节点。而currentRel的子节点(通过getInputs方法获取)是HepRelVertex类型。图结构生成完成以后,会将该图的根节点返回,作为优化流程(findBestPlan)的输入节点。
findBestPlan
HepPlanner 的优化流程就是遍历所有的规则,然后对图中的每个节点应用规则,当然应用规则前会判断当前节点是否适用于当前规则。应用规则的核心代码入口在org.apache.calcite.plan.hep.HepPlanner#applyRules。可以看到,在开始应用规则前,会将图形结构转换成一个迭代器,其实就是节点的一个列表,从图中获取节点列表也就是一个遍历图的过程,而遍历图的算法,有深度优先,广度优先和拓扑排序,HepPlanner 主要提供了深度优先和拓扑排序,默认情况下是深度优先。
将图转换成所有节点的迭代器之后,每遍历到一个节点,都会遍历规则,判断该规则是否适用于该节点,应用规则会生成一个新的节点,因为旧的节点可能被丢弃了,所以此时要么重新生成迭代器要么从新的节点开始生成一个局部的迭代器。代码如下
while (iter.hasNext()) {
HepRelVertex vertex = iter.next();
for (RelOptRule rule : rules) {
HepRelVertex newVertex =
applyRule(rule, vertex, forceConversions);
if (newVertex == null || newVertex == vertex) {
continue;
}
++nMatches;
if (nMatches >= currentProgram.matchLimit) {
return;
}
if (fullRestartAfterTransformation) {
iter = getGraphIterator(root);
} else {
// To the extent possible, pick up where we left
// off; have to create a new iterator because old
// one was invalidated by transformation.
iter = getGraphIterator(newVertex);
if (currentProgram.matchOrder == HepMatchOrder.DEPTH_FIRST) {
nMatches =
depthFirstApply(iter, rules, forceConversions, nMatches);
if (nMatches >= currentProgram.matchLimit) {
return;
}
}
// Remember to go around again since we're
// skipping some stuff.
fixedPoint = false;
}
break;
}
}
org.apache.calcite.plan.hep.HepPlanner#applyRule方法封装了应用单个规则的流程。大致逻辑是先判断规则是否适用于当前节点(matchOperands),如果适用,就生成HepRuleCall对象,它封装了应用规则所需的节点信息,最后应用规则(fireRule)。如果规则执行成功并且生成了新的节点,那么会调用org.apache.calcite.plan.hep.HepRuleCall#transformTo方法将新的节点加入到HepRuleCall定义的结果集中,最后调用方法org.apache.calcite.plan.hep.HepPlanner#applyTransformationResults将新的节点加入图中。
总结
本文总结了 Calcite HepPlanner 的原理以及核心的调用流程,相对于 Calcite 的 VolcanoPlanner,HepPlanner 还是比较简单的,理解概念了,浏览一遍代码基本能弄懂其原理。弄懂 HepPlanner 的原理对设计启发式的优化器和优化规则的帮助是巨大的。