ShardingSphere 查询优化的设计与实现
Apache ShardingSphere的官方定义是一套开源的分布式数据库解决方案组成的生态圈。它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。它们均提供标准化的数据水平扩展、分布式事务和分布式治理等功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。 简单来说,它提供的核心功能就是基于关系型数据库的分库分表(Sharding),读写分离以及分布式事物等能力,再在这些核心能力之上,提供了 Proxy(支持 MySQL 和 PostgreSQL 协议)的能力。由于是用 Java 语言编写,所以实现了 JDBC 规范,方便直接在 Java 代码中使用。此外还提供了分布式治理,弹性伸缩等能力。
在分布式数据库的能力方面,ShardingSphere 还不支持跨库 Join 的能力。去年在学习 Apache Calcite 时与 ShardingSphere 社区沟通过基于 Calcite 实现跨库 Join 的想法,所以近半年时间里,实现了一个大致的框架,并且基于 Calcite 引入了 RBO 和 CBO 的架构。在这个框架下面,可以执行简单的 SQL 语句,可以完成简单的分布式 Join 的查询(不支持 Exchange 算子),但是还远远没有达到完整分布式数据库的目标。下文将对介绍在 ShardingSphere 中实现分布式数据库的能力的一部分设计思路,文中对于什么是分库分表,Sharding 等这些概念不做介绍,建议从网上寻找答案。目前的代码仓库地址:https://github.com/guimingyue/shardingsphere/tree/sharding-executor
Sharding 模式下的跨库 Join
在 Sharding 模式的数据库中,对于每一张被拆分的逻辑表,每一条数据都会经过拆分函数的计算,被路由到指定的分库中的分表。按照执行 Join 的形式,主要有两种,一种是在底层关系型数据库中完成的 Join 操作,这种 Join 在主要在分库中实现,如果 Join 在多个分库中完成,那么上层的计算层还需要做数据合并,这也是 ShardingSphere 所支持的 Join。另一种就是跨库 Join 了,它是指无法在分库上完成,而是需要在分库的上一层的计算层完成的 Join 操作。比如逻辑表 A 表是对主键使用 hash 函数进行拆分,而逻辑表 B 表对主键使用 rang 函数进行拆分,如果它们做 Join 操作,那么可能两张表 join key 分布在不同的分库中,需要另一层计算层来处理计算 Join 条件,并合并数据,那么它们的 join 就属于跨库 join。
所以对于跨库 Join,就需要在计算层计算完成后才能将数据返回。正式因为跨库 join 是在计算层的数据操作,那么如果跨库 Join 的 SQL 语句中使用了聚集函数(group by,sum,min,max,avg 等),也需要在计算层实现这些聚集函数。另外对于部分特定的函数,也需要在计算层实现,比如 SELECT 的列表中,对 join 列执行的函数。
基于这些,在 Sharding 的计算层可以使用一些优化策略,比如将能够下推到分库中的操作尽量下推到分库中执行,无法下推的就在计算层实现。对于 ShardingSphere 来说,如果两张表是 ShardingSphere 中的绑定表,那这两张表的 INNER JOIN 是可以下推到分库中执行的,而如果两张表的拆分算法不一样,那么只能在上层实现 Join 操作。而在上层实现 Join 操作,还可以通过计算不同 Join 算法代价做基于代价的优化。那么如何在 ShardingSphere 的基础上实现跨库 Join 的能力呢?简单一点理解就是实现分布式数据库的计算层,主要有 SQL 解析,SQL 优化,SQL 执行这三个大步骤。
SQL 解析 ShardingSphere 已经有了基于 Antlr 的实现,SQL 优化可以基于 Apache Calcite 来做,SQL 的执行则需要根据 SQL 优化的结果进行实现,不过还是有模型可以参考,那就是 Volcano 执行模型。SQL 优化基于 Calcite 来实现,有一些准备工作,需要利用 Calcite 的元数据接口将 ShardingSphere 的元数据转换成 Calcite 的元数据模型,另外还需要将 ShardingSphere 的 AST 转换成 Calcite 能识别的 AST,这样才能交给 Calcite 去转换成逻辑执行计划,进而做 SQL 优化。总结起来,整个执行过程可以用下图表示。
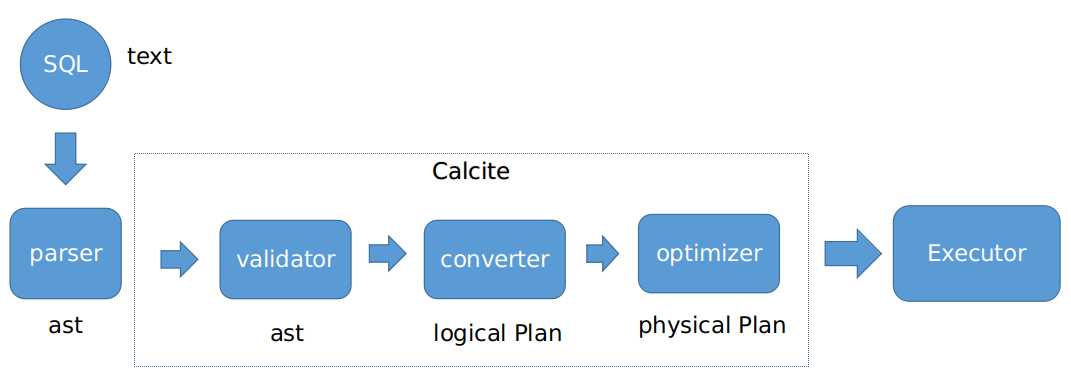
查询优化器
在关系型数据库中,查询优化以关系代数为基础,目的是将关系代数表达式优化成一个最优的物理执行计划(仍然是关系代数表达式)交给执行引擎去执行。优化过程会涉及到关系代数的转换和优化两个过程。转换也称为重写,它的输入是一个逻辑关系代数表达式,输出仍然是逻辑关系代数表达式。优化则不一样,该过程会根据优化规则,将逻辑关系代数表达式中的各个算子,优化成物理算子交给优化器执行计算代价,最终确定代价最低的物理执行计划,所以优化过程的输入是逻辑关系代数表达式,而输出则是物理关系代数表达式,该表达式中各个物理算子表明了执行器的执行算法。
Sharding 模式的查询优化属于一种分布式查询优化,而分布式查询优化以减少传输的次数和数据量作为查询优化的目标,分布式数据库系统中的代价估算模型,除了考虑CPU代价和IO代价外,还要考虑通过网络在结点间传输数据的代价。在目前的实现中,优化器是基于 Calcite 的查询优化器 HepPlanner 和 VolcanoPlanner。HepPlanner 主要用于逻辑查询计划的重写,是基于规则的启发式的优化,而 VolcanoPlanner 则是基于代价的优化,由于还未定义代价模型以及统计数据,目前只是用于将逻辑算子转换为物理算子。关于 Calcite 的 HepPlanner 优化器和优化规则,可以参考如下两篇文章。
逻辑查询计划重写
逻辑查询计划重写是一种启发式的手段,也称为基于规则的优化(RBO),会按照优化规则将关系代数表达式中的部分算子改写,输出一个改写后的关系代数表达式,这些规则必须是确保新生成的整个表达式是与重写前的关系代数表达式等价的。Sharding 模式的逻辑查询计划重写的优化策略就是下推,一种是算子的下推,典型的是将 join 之上的 filter 下推到 join 下面。另一种是一部分算子整体下推到分库所在的数据库层,因为分库分表模型的存储层是有计算能力的,所以可以将 tablescan + filter 一起下推到分库上执行,也可以将符合条件的join下推到分库上执行,这一点与存储计算分离的分布式数据库不同。在这次的实现中,定义了新的逻辑算子 LogicalScan,用于表示可以下推到分库上执行的算子集合。在执行时会将整个 LogicalScan (对应的物理算子 SSScan)算子转换成能在分库上执行的 SQL 语句。
比如,对于如下 SQL 语句,
select o1.order_id, o1.order_id, o1.user_id, o2.status from t_order o1 join t_order_item o2
on o1.order_id = o2.order_id where o1.status='FINISHED' and o2.order_item_id > 1024 and 1=1
经过转换后,其逻辑执行计划示意图如下图左边所示。Filter 算子在 Join 之上,经过重写优化,可能会被转换为下图右边的形式,Filter 被下推到 Join 下面,并且 Filter 可以和下面的 TableScan 一起下推成 LogicalScan。图中的 LogicalScan 算子就是可以下推到分库上执行的逻辑算子。如果 Join 的两张表是 ShardingSphere 的绑定表,并且是可以下推到分库上执行的 Join(比如 INNER JOIN),那么还可以继续下推,将左右两边的 LogicalScan 和 Join 一起下推成一个新的 LogicalScan。
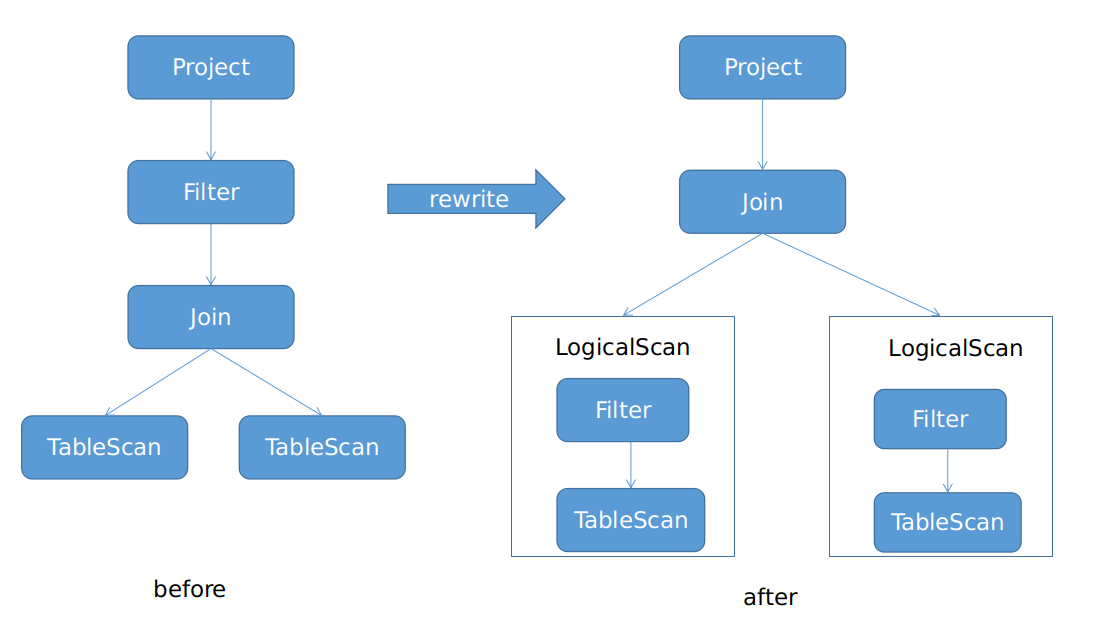
基于代价的优化
由于还没有引入统计信息,所以目前只是利用 Calcite 的基于代价的优化器 VolcanoPlanner 实现了逻辑执行计划到物理执行计划的转换。比如对于上面的 SQL 语句对应的重写后的逻辑执行计划,最终转换而成的物理执行计划可能如下图所示。
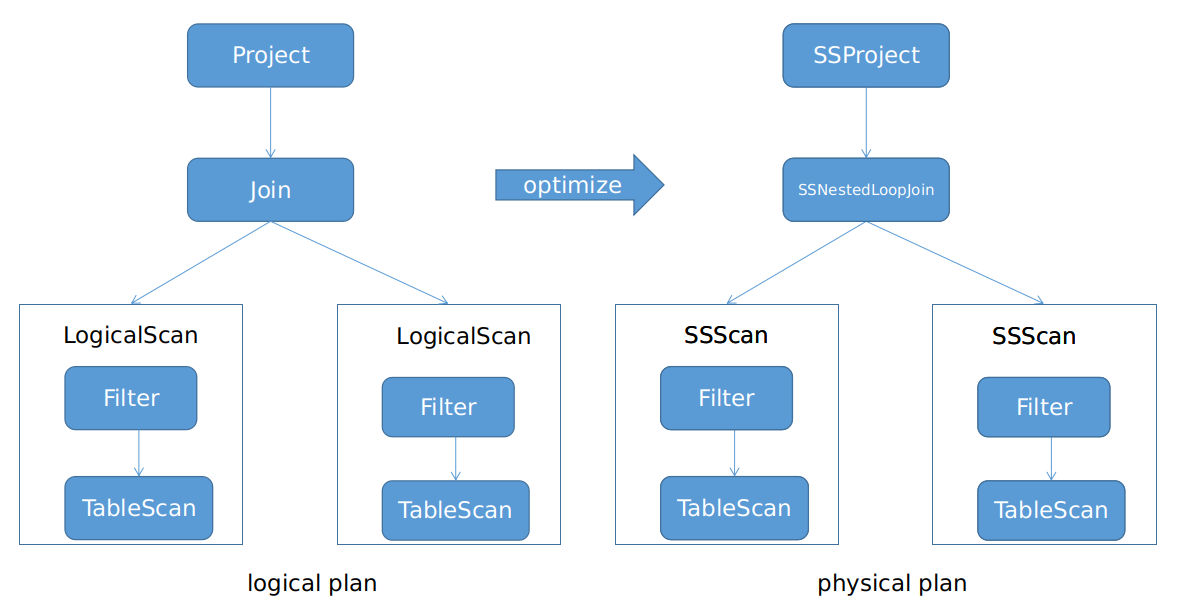
图中右边的就是物理执行计划,SSScan 算子与 LogicalScan 对应,它表示一个下发到分库上执行的执行计划,最终会转换成与分库的数据库相关的 SQL 语句去执行,如果分库的数据库是 MySQL,那么就会转换成 MySQL 对应的 SQL 语句。SSNestedLoopJoin 就是 join 对应的物理算子,该算子会使用 nested loop join 算法来实现表的连接操作。
执行器
执行器是一个标准的 Volcano 执行器模型,在该模型中,每一种物理算子都会对应一个迭代器,这个迭代器提供一组简单的接口:open — next — close,物理查询计划被转换成执行模型树,每一次的 next 调用,就返回一行数据,每一个算子对应的迭代器的 next 都有自己的流控逻辑,数据通过自上而下的 next 嵌套调用而被动的进行行的拉取。目前实现的执行器的接口是 Executor,定义了 init,moveNext和close这三个与 open — next — close 对应的接口方法,还定义了 current接口方法返回当前行。通过 moveNext 方法,定义访问下一行数据的操作,通过current方法定义访问当前的行。
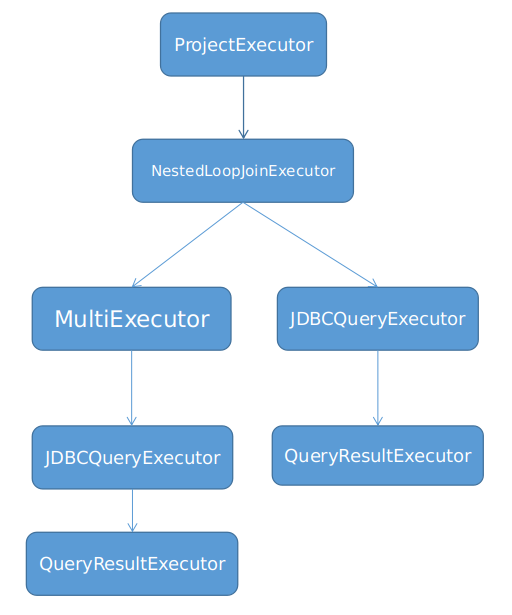
对应于上述的物理执行计划的 Volcano 执行器模型结构如下图所示。ProjectExecutor 和 NestedLoopJoinExecutor 分别对应与物理执行计划中的物理算子,而 SSScan 则对应与 MultiExecutor 和 JDBCQueryExecutor。因为 SSScan 为下推到分库上执行的语句,可能会下推到多个分库,所以对于下推到多个分库的结果,使用 MultiExecutor 来封装,对上层只暴露一个 Executor 对象。JDBCQueryExecutor 下层是 QueryResultExecutor,它是对 ShardingSphere 在分库上执行结果 QueryResult 的 Executor 包装。
总结
本文首先介绍了在基于 Sharding 模式下做分布式查询优化所需要解决的问题,然后介绍了基于 Apache Calcite 的查询优化的设计以及实现思路,包括逻辑执行计划重写和物理执行计划的转换,最后介绍了基于 Volcano 执行器模型的执行器框架。做到这一步就实现了一个简单的查询优化器以及对应的执行器,但是查询优化器和执行器远远没有这么简单,比如如何做到基于代价的优化,如何实现 Hash 以及流式的聚合等等,这些都待以后来逐步实现。
Reference
- http://shardingsphere.apache.org/
- 《数据库查询优化的艺术》,作者李海翔
- https://calcite.apache.org/